-
Nie Lin, Lingbo Liu#, Zhengtao Wu, Wenxiong Kang. "Unconstrained Face Sketch Synthesis via Perception-Adaptive Network and A New Benchmark", Neurocomputing 2022.
Paper
Source Code: [Github]
WildSketch Dataset: [Dropbox] [BaiDuYun (Password:4jbd)]
Results: [Dropbox] [BaiduYun (PW: face)]
WildSketch Benchmark
In this work, we introduce the first medium-scale dataset for unconstrained face sketch synthesis. Our dataset contains 800 pairs of highly-aligned face photo-sketch, which is of better quality and larger scale than the popular CUHK dataset and AR dataset. More specifically, 400 pairs are randomly chosen for training and the rest are for testing. Our WildSketch is much more challenging, as there are more variations in pose, age, expression, background clutters, and illumination, as shown below. We do hope that the proposed WildSketch benchmark could significantly promote researches in the field of face sketch synthesis.

Method
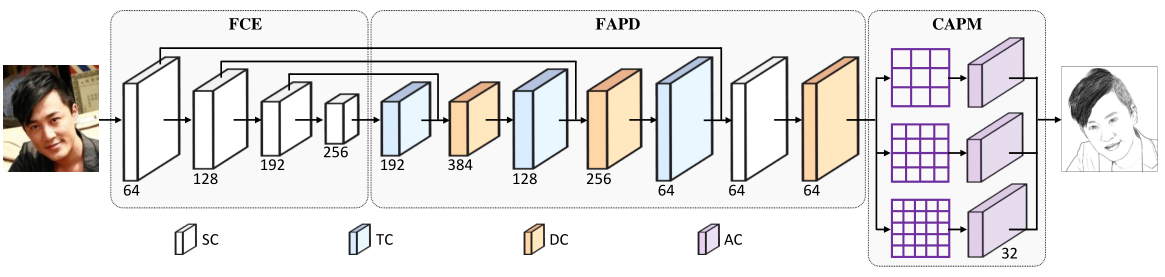
In this work, we propose a novel Perception-Adaptive Network (PANet) for face sketch synthesis in the wild. Specifically, our PANet is composed of i) a Fully Convolutional Encoder for hierarchical feature extraction, ii) a Face-Adaptive Perceiving Decoder for extracting potential facial regions and handling face variations, and iii) a Component-Adaptive Perceiving Module for facial component aware feature representation learning. First, the FCE takes an unconstrained image as input and extracts the hierarchical features with consecutive standard convolutional layers and pooling layers. Then, incorporating the deformable convolutional layers, the FAPD dynamically learns the offset of convolution and implicitly attends the potential face regions to better capture the facial appearance variation. Third, the CAPM divides the feature map of the unaligned face into multi-scale regions, each of which may contain a specific facial component. For each region, CAPM dynamically generates the filter weights based on its content with adaptive convolutional layers, and then convolve its feature with the computed weights to generate a specialized feature for the potential facial component in this region. Finally, the filtered features of all regions are combined to synthesize a high-quality sketch.
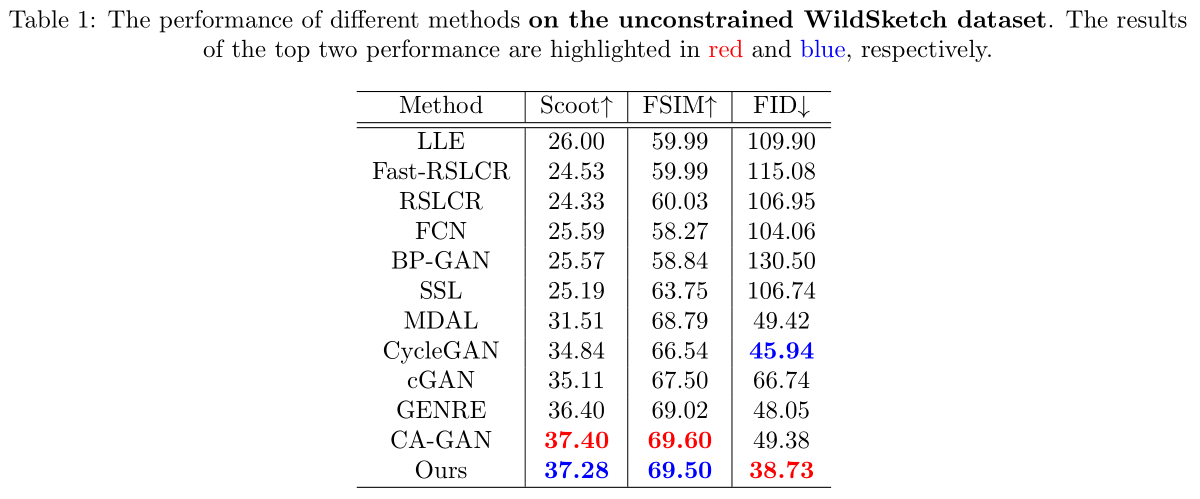
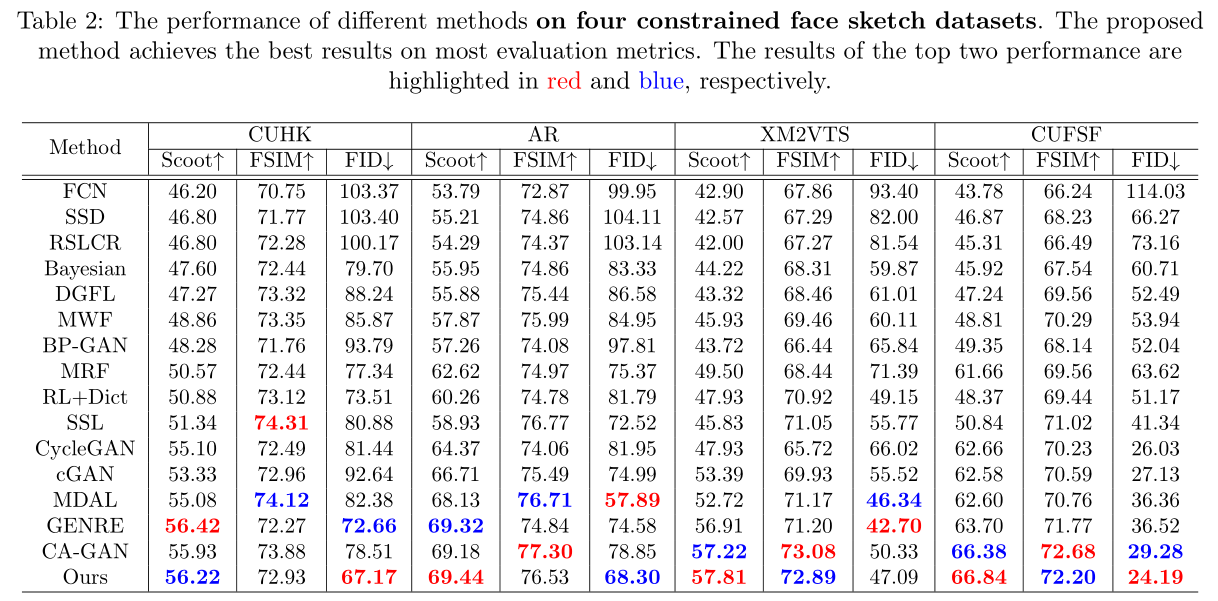
Experiments