-
SHMetro Dataset: a large-scale dataset for metro ridership prediction [Download]
- 288 metro stations in Shanghai, China.
- Totally 811.8 million transaction records (7/01/2016-9/31/2016).
- For each station, the inflow and outflow of every 15 minutes are measured.
Related Work: Physical-Virtual Collaboration Modeling for Intra-and Inter-Station Metro Ridership Prediction
-
HZMetro Dataset: a large-scale dataset for metro ridership prediction [Download]
- 80 metro stations in HangZhou, China.
- 2.35 million ridership per day (01/01/2019-01/25/2019).
- For each station, the inflow and outflow of every 15 minutes are measured.
Related Work: Physical-Virtual Collaboration Modeling for Intra-and Inter-Station Metro Ridership Prediction
-
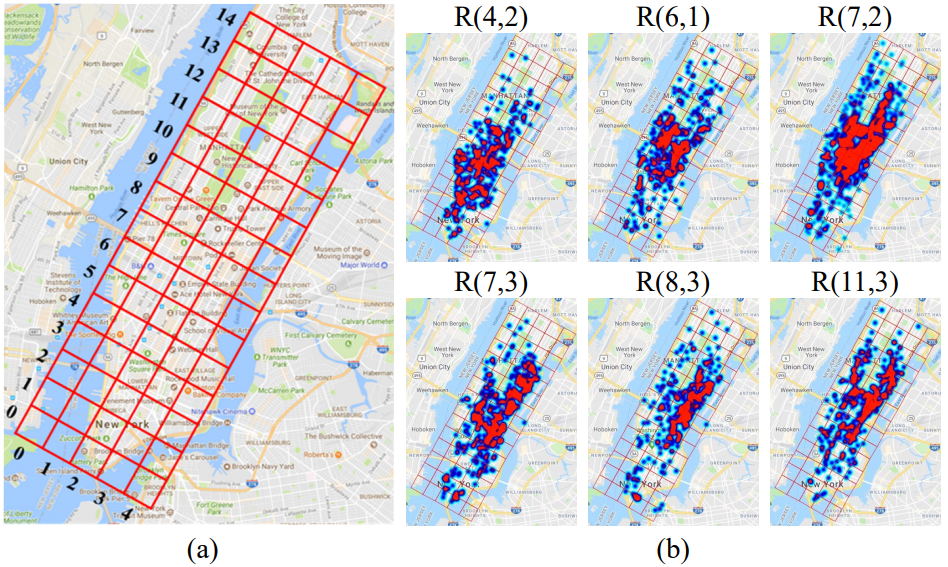
NYC-TOD Dataset: a large-scale dataset for taxi origin-destination demand prediction [Download]
- We diveded the New York City into a 15×5 grid map.
- A total of 132 million taxi trip records in 2014.
- We measured the taxi demands between every two regions during each 0.5 hour.
Related Work: Contextualized Spatial-Temporal Network for Taxi Origin-Destination Demand Prediction
-
TaxiNYC Dataset: a large-scale dataset for taxi pickup/dropoff prediction [Download]
- The New York City is diveded into a 15×7 grid map.
- A total of 132 million taxi trip records in 2014.
- For each region, the taxi pickup/dropoff demand of every 30 minutes are measured.
Related Work: Dynamic Spatial-Temporal Representation Learning for Traffic Flow Prediction
Data Mining Datasets
-

RGBT Crowd Counting Benchmark : a large-scale RGBT dataset for crowd counting [Download]
- It contains consists of 2,030 pairs of 640x480 RGB-thermal images captured in various scenarios.
- 1,013 pairs are captured in the light and 1,017 pairs are in the darkness.
- A total of 138,389 pedestrians are marked with point annotations, on average 68 people per image.
Related Work: Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
-

SYSU16K Landmark Dataset: a large-scale dataset for facial landmark localization in the Wild [Download]
- It contains 7317 images with 16K faces collected from the Internet.
- Each face is accurately annotated with 72 landmarks.
- The faces on this dataset exhibit various pose, expression, illumination and resolution, and may have severe occlusions.
Related Work: Facial Landmark Machines: A Backbone-Branches Architecture with Progressive Representation Learning
-

WildSketch Dataset: the first medium-scale benchmark for unconstrained face sketch synthesis [Download]
- It contains 800 pairs of highly-aligned face photo-sketch.
- WildSketch is of better quality and larger scale than the popular CUHK dataset and AR dataset.
- WildSketch is much more challenging for large variations in pose, expression, ethnic origin, background, and illumination.
Related Work: Unconstrained Face Sketch Synthesis via Perception-Adaptive Network and A New Benchmark
Computer Vision Datasets